Dual Channel Dual Staging: Hierarchical and Portable Staging for GPU-Based In-Situ Workflow
Abstract
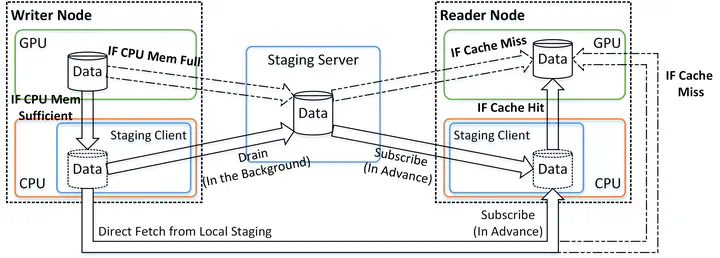
In-situ workflows have emerged as an attractive approach for addressing data movement challenges at very large scales. Since GPU-based architectures dominate the HPC landscapes, porting these in-situ workflows, and, specifically, the inter-application data exchange, to GPU-based systems can be challenging. Technologies such as GPUDirect RDMA (GDR), which is typically used for I/O in GPU applications as an optimization that circumvents the CPU overhead, can be leveraged to support bulk data exchanges between GPU applications. However, current GDR design often lacks performance portability across HPC clusters built with different hardware configurations. Furthermore, the local CPU may also be effectively used as an auxiliary communication mechanism to offload data exchanges. In this paper, we present a dual channel dual staging approach for efficient, scalable, and performance-portable inter-application data exchange for in-situ workflows. This approach exploits the data access pattern within in-situ workflows along with the inherent execution asynchrony to accelerate data exchanges and, at the same time, improve performance portability. Specifically, the dual channel dual staging method leverages both the local CPU and the remote data staging server to build a hierarchical joint staging area and uses this staging area to transform blocking inter-application bulk data exchanges into best-effort local data movements between GPU and CPU. The dual channel dual staging is implemented as a portability extension of the Dataspaces-GPU staging framework. We present an experimental evaluation of its performance, portability, and scalability using this implementation on three leadership GPU clusters. The evaluation results demonstrate that the dual channel dual staging method saves up to 75% in data-exchange time compared to host-based, GDR, and alternate portable designs, while maintaining scalability (up to 512 GPUs) and performance portability across the three platforms.